
May 21, 2024

Human-Like Agents for Enterprise
Can AI Agents be complaint, secure, scalable and stable for your use case? Lets look at the tech behind.
A. Cutting-Edge Technologies Powering Our Solutions
1. Large Language Models (LLMs)
Currently language understanding is human-like, even scoring more than average humans in top tests like GMAT, SAT etc. It makes the models empathetic, human-level intelligence to understand and respond to customer needs.
Here is a simple chat example with a LLM:
LLMs today are beating humans in most tests, here is ChatGPT-3.5 and ChatGPT-4 test scores compared:
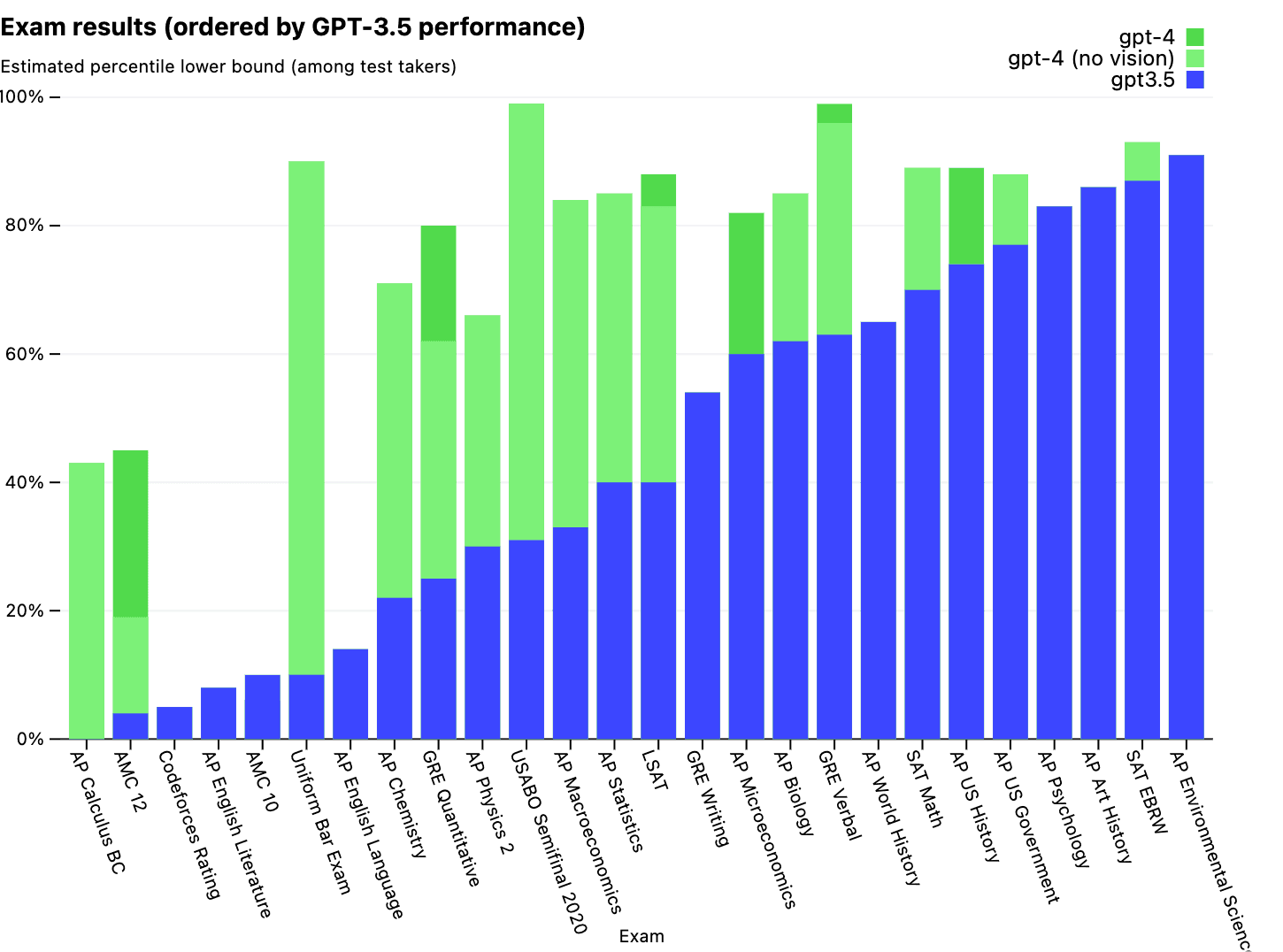
Source: GPT-4 launch blog post from OpenAI
Here GPT-4 is performing on average more than 80 percentile in most tests, with GPT-4-turbo and GPT-4o performing even better than this. This shows how flexible and broad knowledge an LLM has and its capability in answering like and solving problem like humans.
This level of understanding and broad knowledge is made possible by innovation in Machine Learning model architecture, specifically the Transformer Model, humongous amount of quality data curated by human intervention in multiple steps as shown below and training them efficiently on 1000s of GPUs. Here is openAI's method of data selection and improvement, and training:
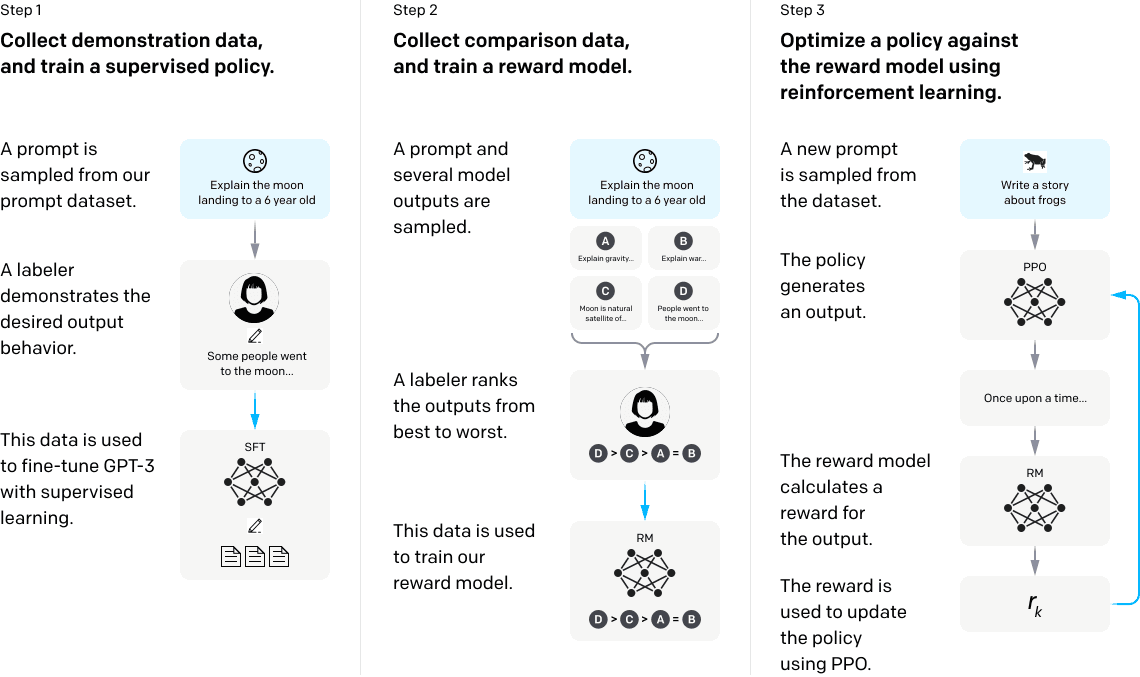
Source: OpenAI paper titled "Training language models to follow instructions with human feedback"
2. Ultra Realistic Voices
Today we have Ultra Realistic AI Human-Like Voices which can be made in real time (less than 1/2 a second) with different emotions! And this can be done for 100+ languages now! Here are some example voices generated using PlayHT's API:
3. Real Time Text-To-Speech
After more than a decade of innovation in Speech-To-Text today is near real-time fast with word error rate (WER) of less than 10%. With Deepgram STT service being the fastest and with lowest error rates on average.
Deepgram STT model word error rate (WER) comparison:
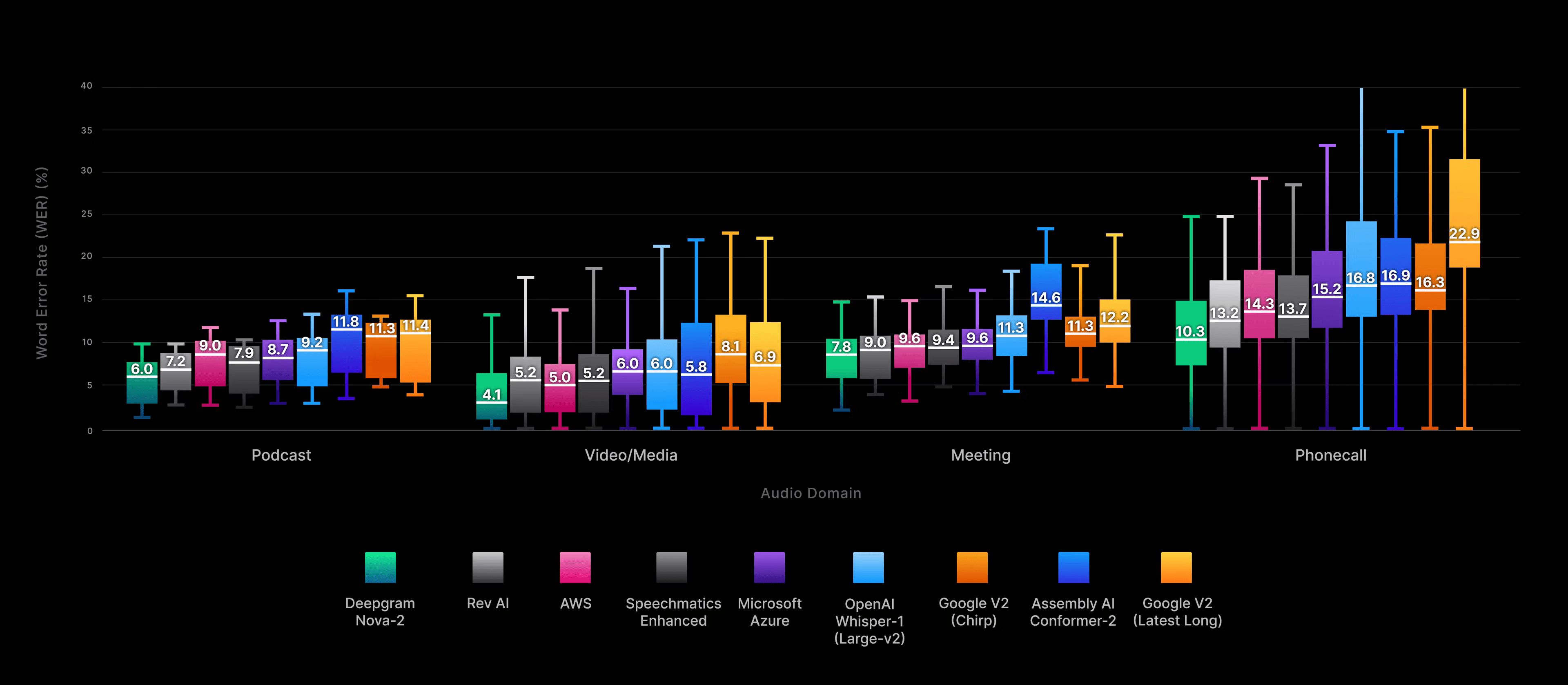
Source: Deepgram 2024 Model comparison blog [Link]
Deepgram STT model speed comparison:
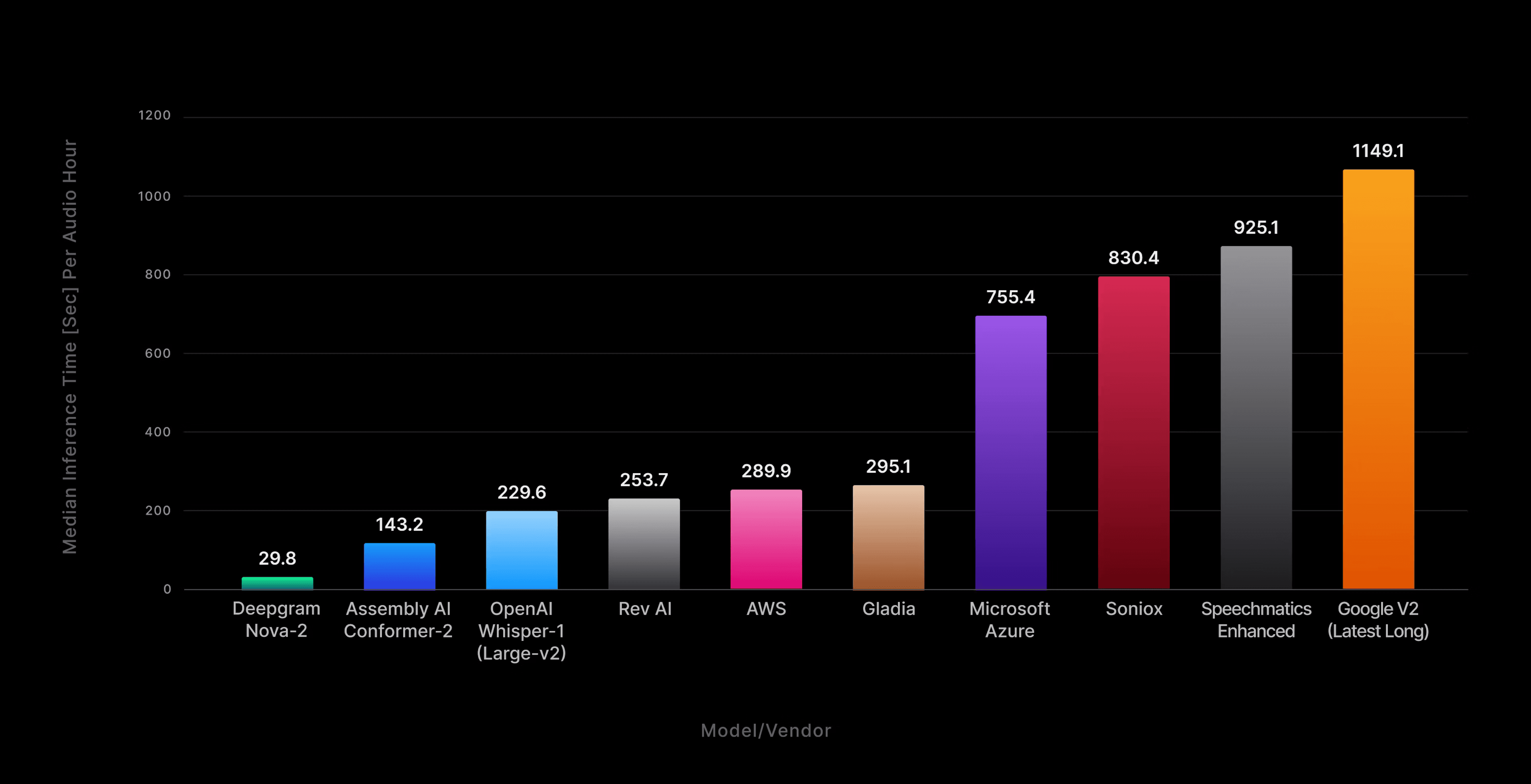
Source: Deepgram [Link]
4. Multi-Modal Models
A blend of text, audio, and video capabilities, preparing you for the future of AI interactions.
As already seen after launch of GPT-4o, these will make a perfect human-like AI Agents, as they will be able to read text, listen to audio and see images/videos like humans do with a single model!
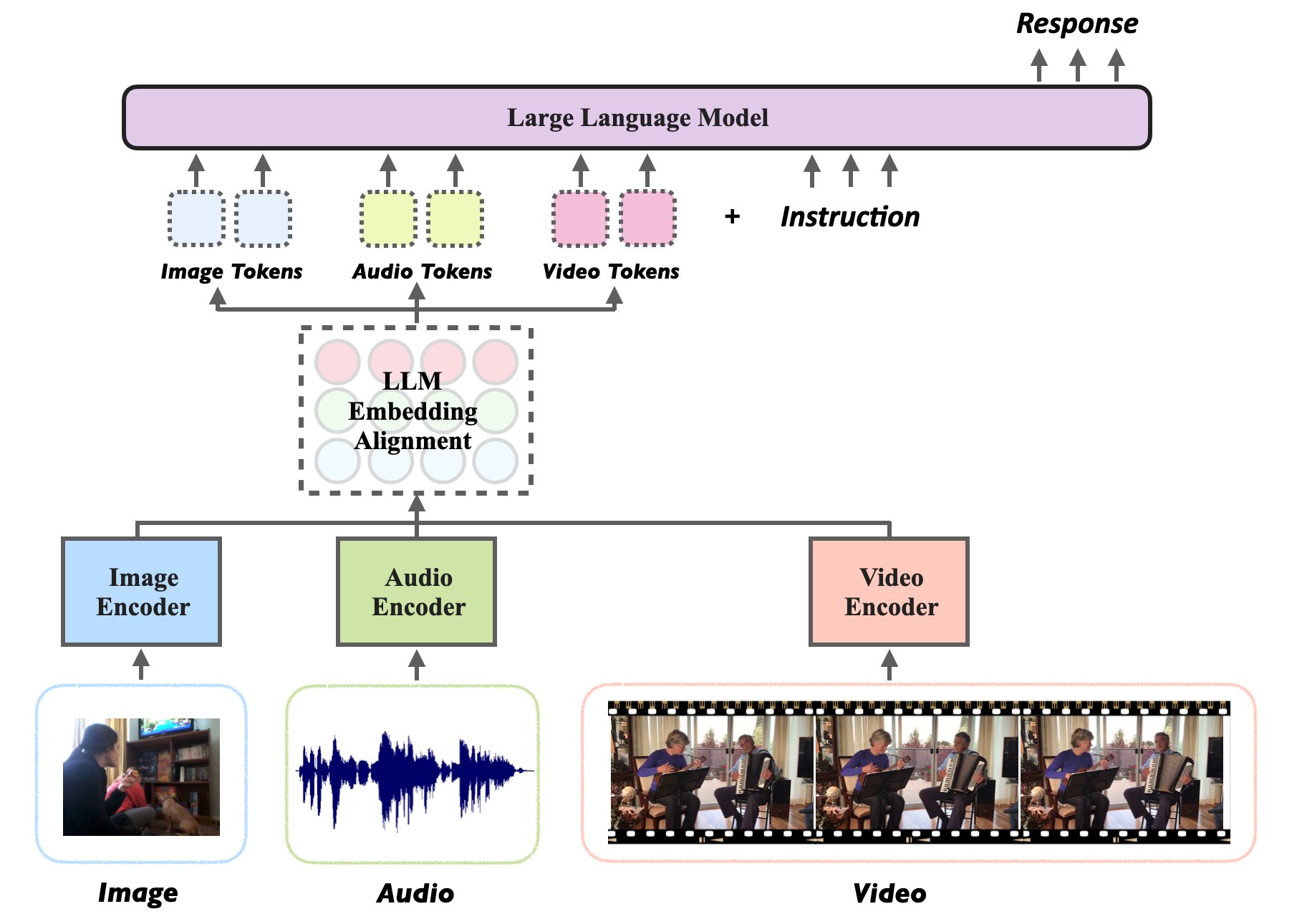
Source: Twitter
B. Ensuring Reliability in AI Interactions
We proactively address common technological challenges to maintain high-quality service.
Hallucinations:
Fine Tuning: Continuously improving the model's responses through targeted domain-specific training.
Limiting Context and Boundary Setting: Ensuring responses remain relevant and within the scope of expected interactions.
Industry Specific Terminologies:
Fine Tuning: Training our models to understand and use industry-specific jargon correctly.
Retrieval assisted generation (RAG): Search in a predefined list of terminologies and generate response based on that.
Empathy and Patience:
Prompt Engineering: Designing prompts that encourage empathetic and patient responses.
Fine Tuning: Refining models to better understand and react to human emotions.
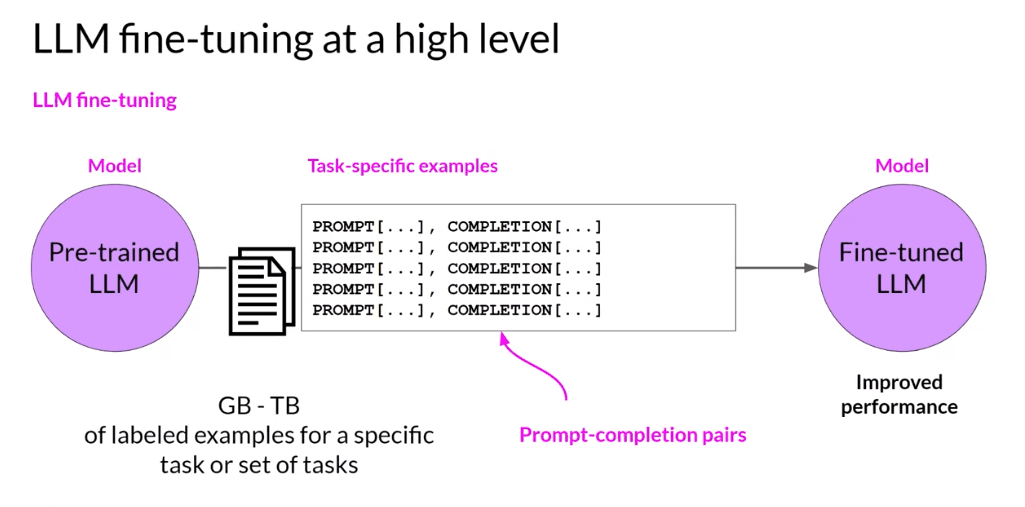
Source: Medium

Source: OpenAI - Techniques for optimizing LLM's performance [Link]
Complexity and cost implications of different methods to improve model's performance:
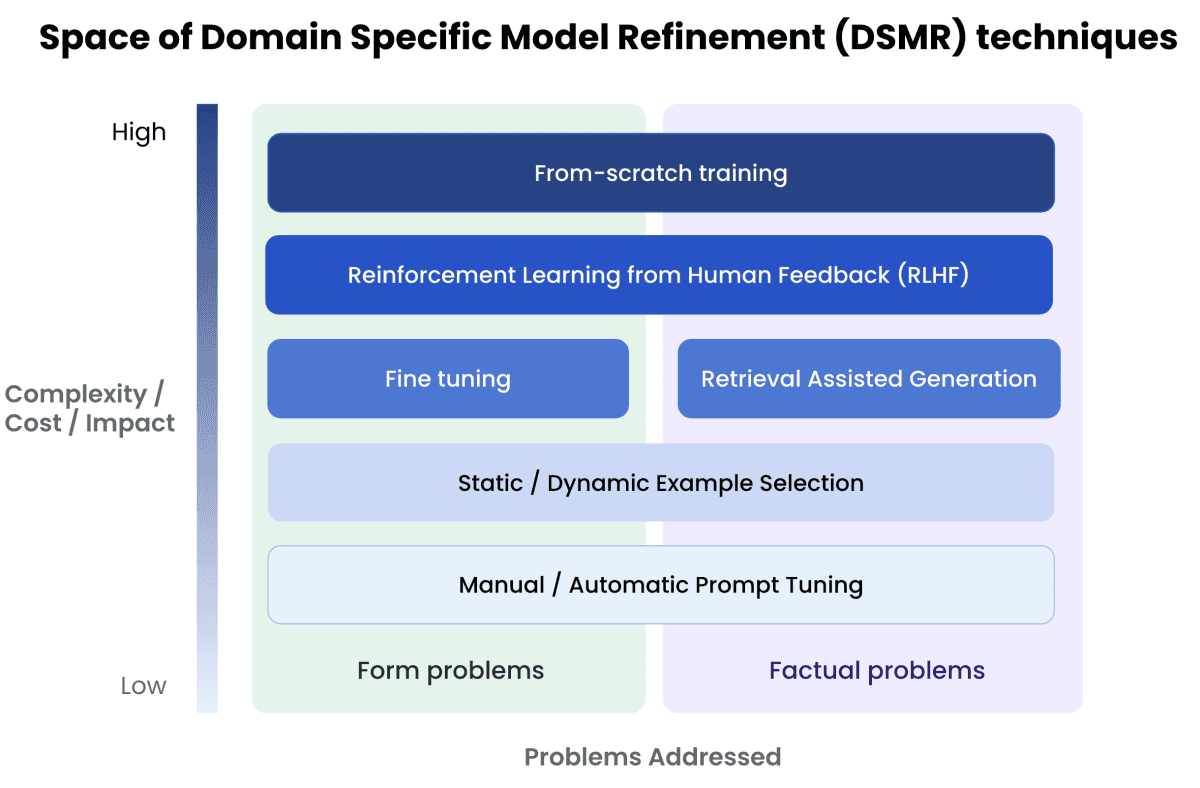
Source: AnyScale Blog [Link]
C. Onboarding Process
Onboarding process designed to integrate seamlessly with your existing operations, ensuring a smooth transition and effective deployment.
Setting objective and KPIs: From past data identify top queries that agents get and define an objective and KPIs based on that.
Requirement Gathering: Detailed collection of your requirements (data, API access to CRM, CCaaS etc.) to ensure our solution meets your needs.
Implementation and Fine Tuning: Develop and test the solution in stages. Optimize as per the required accuracy level using Prompt Engineering, RAG and Fine Tuning.
Integration Testing: Rigorous testing on small scale on days to weeks of timeframe to guarantee seamless integration.
Roll Out and Monitoring: We launch and continuously monitor the system to ensure optimal performance and adjustments.
